Natural Language Toolkit (NLTK) – Sprache mit Python auswerten
Bei der Bibliothek NLTK (Natural Language Toolkit) kann ideal in der Computerlinguistik genutzt werden. Damit können natürliche Sprache algorithmisch verarbeitet werden.
Hier soll die einfache Anwendung in Form von der Auswertung von Worthäufigkeiten gezeigt werden und die Ausgabe einer Grafik über die Wörterhäufigkeitsverteilung. Das schöne ist, wie einfach dies über die NLTK-Bibliothek möglich ist.
Im ersten Schritt muss in Python die NLTK-Bibliothek über PIP installiert werden:
pip install nltk
Jetzt können wir die Bibliothek auf Text loslassen. Als Erstes müssen wir diese aktivieren durch import nltk und dann benötigen wir einen Text. Wir nutzen die bekannte Ballade „Erlkönig“ von „Wolfgang von Goethe“. Den kompletten Text gibt es bei Wikipedia unter:
https://de.wikipedia.org/wiki/Erlk%C3%B6nig_(Ballade)
import nltk
inhalt = """Der Erlkönig
Wer reitet so spät durch Nacht und Wind?
Es ist der Vater mit seinem Kind;
Er hat den Knaben wohl in dem Arm,
er faßt ihn sicher, er hält ihn warm.
Mein Sohn, was birgst du so bang dein Gesicht?
Siehst, Vater, du den Erlkönig nicht?
Den Erlkönig mit Kron und Schweif? -
Mein Sohn, es ist ein Nebelstreif. -
"Du liebes Kind, komm geh mit mir!
"""
woerter = inhalt.split()
worthaeufigkeit = nltk.FreqDist(woerter)
print(worthaeufigkeit)
print(worthaeufigkeit.most_common())
Unseren Text in der Variable inhalt wandeln wir über die Funktion split() in eine Liste mit dem Namen woerter um, die wir mit Methoden unserer Bibliothek nltk nutzen können. Über die Methode most_common() erhalten wir die Verteilung - als Ergebnis bekommen wir angezeigt:
python3 worthaeufigkeit-erlkoenig.py
[('Erlkönig', 3), ('mit', 3), ('so', 2), ('und', 2), ('ist', 2), ('den', 2), ('er', 2), ('ihn', 2), ('Mein', 2), ('Sohn,', 2), ('du', 2), ('-', 2), ('Der', 1), ('Wer', 1), ('reitet', 1), ('spät', 1), ('durch', 1), ('Nacht', 1), ('Wind?', 1), ('Es', 1), ('der', 1), ('Vater', 1), ('seinem', 1), ('Kind;', 1), ('Er', 1), ('hat', 1), ('Knaben', 1), ('wohl', 1), ('in', 1), ('dem', 1), ('Arm,', 1), ('faßt', 1), ('sicher,', 1), ('hält', 1), ('warm.', 1), ('was', 1), ('birgst', 1), ('bang', 1), ('dein', 1), ('Gesicht?', 1), ('Siehst,', 1), ('Vater,', 1), ('nicht?', 1), ('Den', 1), ('Kron', 1), ('Schweif?', 1), ('es', 1), ('ein', 1), ('Nebelstreif.', 1), ('"Du', 1), ('liebes', 1), ('Kind,', 1), ('komm', 1), ('geh', 1), ('mir!', 1)]
Hier fallen die Satzzeichen auf, die problematisch werden können. Uns interessiert nicht wirklich, wie viele Gedankenstriche vorkommen und Satzzeichen beim Wort oben wie im Beispiel „Gesicht?“. Also beseitigen wir die Satzzeichen komplett:
import nltk
inhalt = """Der Erlkönig
Wer reitet so spät durch Nacht und Wind?
Es ist der Vater mit seinem Kind;
Er hat den Knaben wohl in dem Arm,
er faßt ihn sicher, er hält ihn warm.
Mein Sohn, was birgst du so bang dein Gesicht?
Siehst, Vater, du den Erlkönig nicht?
Den Erlkönig mit Kron und Schweif? -
Mein Sohn, es ist ein Nebelstreif. -
"Du liebes Kind, komm geh mit mir!
"""
satzzeichen = (",", ";", ":", ".", "?", "!", '"', '-', '–')
for unerwuenschtes in satzzeichen:
inhalt = inhalt.replace(unerwuenschtes, "")
bereinigt = inhalt.split()
worthaeufigkeit = nltk.FreqDist(bereinigt)
print(worthaeufigkeit.most_common())
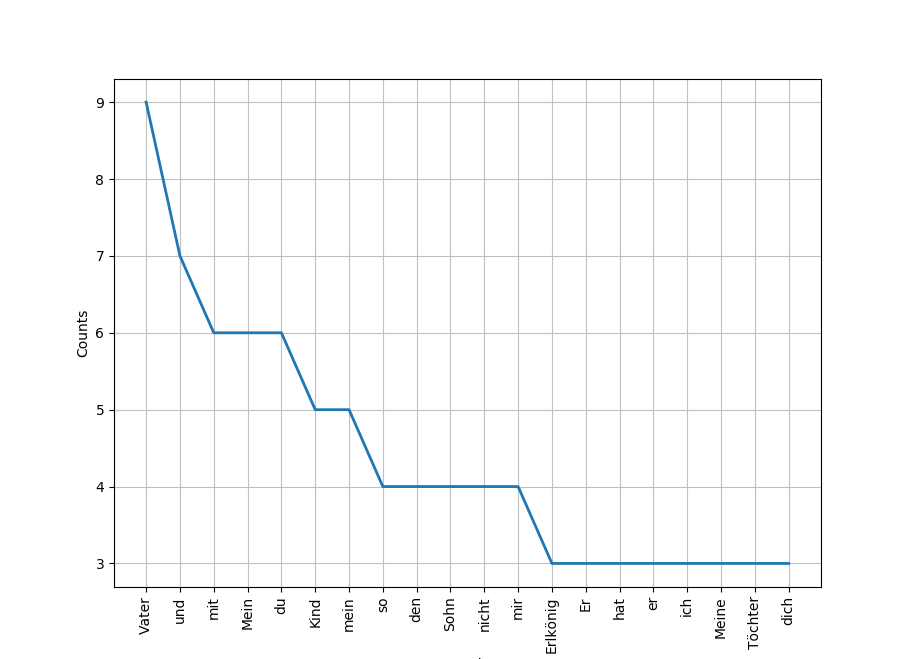
Jetzt bekommen wir die Auswertung der Worthäufigkeiten, die wir über die Angabe in der Klammer auf eine gewünschte Ausgabeanzahl über print(worthaeufigkeit.most_common(20)) einschränken können. Für die gesamte Ballade die Häufigkeit der ersten 20 Begriffe:
[('Vater', 9), ('und', 7), ('mit', 6), ('Mein', 6), ('du', 6), ('Kind', 5), ('mein', 5), ('so', 4), ('den', 4), ('Sohn', 4), ('nicht', 4), ('mir', 4), ('Erlkönig', 3), ('Er', 3), ('hat', 3), ('er', 3), ('ich', 3), ('Meine', 3), ('Töchter', 3), ('dich', 3)]
Und über die weitere Anweisung print(worthaeufigkeit.plot(20)) erhalten wir die grafische Auswertung:
Dies hier als kleine Einführung in eine extrem umfangreiche Bibliothek. Viele Informationen finden sich auf der Website https://www.nltk.org/ des Projekts.
